Software Heritage for Open Science

On july 4th 2018 was unveiled the French national plan for Open Science, that identifies Software Heritage as one key initiative to support. Today we are delighted to welcome the French Ministry of Research as our first gold sponsor, contributing effectively to our efforts. We are very grateful for this institutional support, and we look forward to see many others follow this example.
On this occasion, we are happy to recall why Software Heritage is building an infrastructure that plays a key role for Open Science.
Making Science Open
Open Science is an important movement that wants to render accessible to all the results of public research.
One of the many goals of this movement is to tear down the walls and barriers that have emerged over the past decades, when the spectacular economies generated by the advent of modern information and communication technology have been absorbed by private stockholders instead of being passed over to researchers and funding agencies, converting the traditional marriage of interest between publishers and researchers into a long and painful divorce process.
Another important goal is to try and address the deep reproducibility crisis, in particular by facilitating access, understanding, verification and reuse of the various ingredients of the research and publication process.
Software is a key ingredient of Open Science
Software has become today one of these ingredients, and an essential one, for research activities in all disciplines: 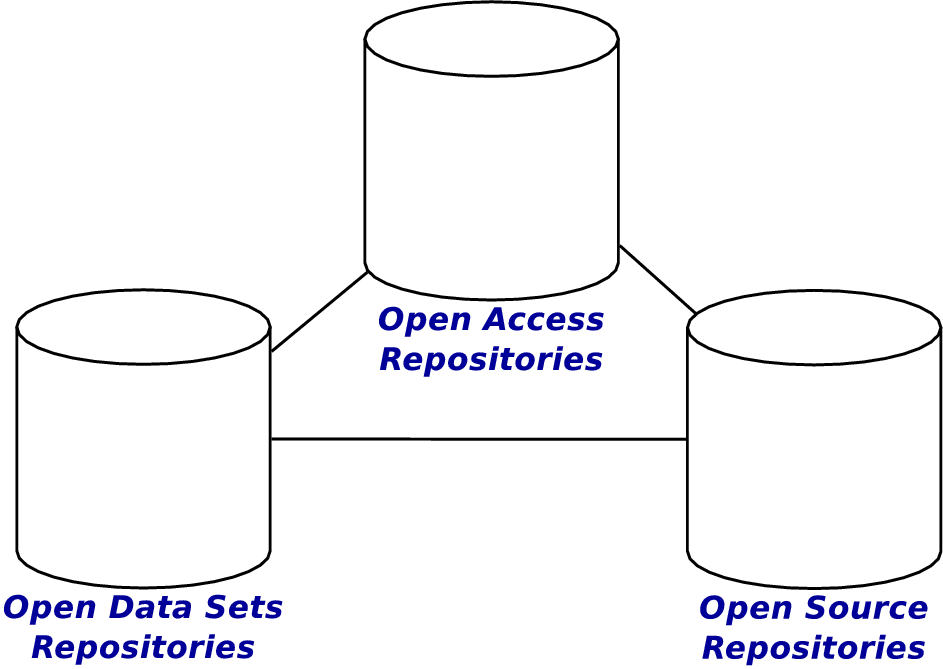
from physics to biology, from mathematics to linguistics, from law to social sciences, computer programs are used everywhere. In order to understand, replicate, verify and reuse a research result, it is necessary to have access to the article that describes it, as well as to the data and the computer programs used to obtain it.
And to really understand what a computer program does, and to adapt it to new research, we need access to its source code.
Software Heritage at the service of Open Science
This is why our work here at Software Heritage is of particular relevance for Open Science.
By building a long term, non for profit, shared infrastructure that collects, preserves and makes easily available the source code of all software that is publicly available, we are actually contributing to build the long overdue software pillar of Open Science.
Indeed, software is quite different from data, and requires specific design decisions. Here are some of the key features that make Software Heritage so special:
- we provide intrinsic identifiers for all the software we archive: intrinsic identifiers allow to track software source code artifacts at different granularity, without relying on trusted third parties
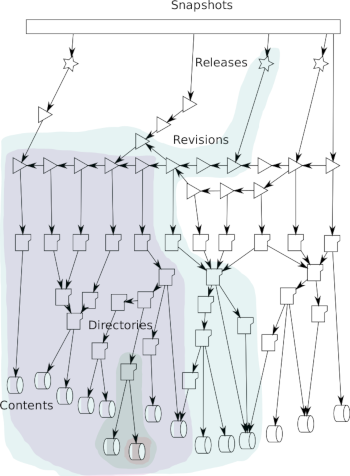
- we ingest software source code from all origins into a single, uniform, simple data model based on Merkle trees, a design choice that
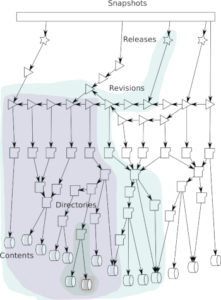 allows to:
allows to:
- abstract away details like the particular version control system or development platform used;
- ease access to the archive content over the long term, by removing the dependency on complex tools;
- contain operational costs, by massively reducing the storage space needed
- we archive all the software source code, not only research software, as research software depends on a wealth of other software, from operating systems to generic libraries and tools
{kind=link}
Leveraging these unique features, it is now finally possible to write research articles that reference research software in a new, enhanced way, and we are providing detailed guidelines to this end.