Paving the way for open and responsible artificial intelligence with Software Heritage

Back in 2014, we were two computer scientists with a question: How can we safeguard the patrimony of source code?
Finding an answer was more than an academic exercise. Between us, we had decades of contributions to open-source projects and witnessed what happens when code ‘disappears.’ The Four Freedoms are fundamental to modern software development but no one can run, study, modify, or share what has gone missing due to platform collapse or deprecated servers.
With support from Inria, France’s National Institute for Research in Digital Science and Technology, Software Heritage launched in June 2016 with a clear mission: to serve as a universal archive for all software. In April 2017, UNESCO and Inria partnered to support this massive undertaking.
What’s next: CodeCommons
Ten years later, we’re taking on a new question: How can the software commons evolve to benefit everyone in the artificial intelligence era?
We started building a foundation for that answer with a Statement on Large Language Models for Code in 2024. The statement rests on three principles:
- Code from the SWH archive must be given back to humanity, rather than monopolized for private gain.
- Initial training data from the Software Heritage archive must be fully and precisely identified (for example, publishing corresponding SWHID identifiers)
- Authors must be able to exclude their archived code from model training inputs.
Committed to these principles, the BigCode project gained access to the archive and released the StarCoder2 model in February 2024, proving that such adherence doesn’t hinder innovation. StarCoder2 is a model trained on a transparent subset of GitHub-hosted repositories archived by Software Heritage.
A few shortcomings in the way public code is used for LLMs became immediately apparent:
- Wasted resources, inconsistency: Right now, anyone who wants to train a model starts with an individual download of massive amounts of publicly available code from sources like GitHub. All this downloading is a huge waste of bandwidth, storage and compute resources. Datasets downloaded individually often have slight variations, hobbling scientific reproducibility and accurate comparisons between models
- Redundant data processing: Each team must clean and organize the raw data, filtering out duplications. Software Heritage’s archive, by contrast, is organized as a fully-deduplicated Merkle graph, avoiding redundancy that many projects are forced to address independently.
- License and quality issues: Some projects attempt to include only correctly-licensed code but often fall short due to challenges around identifying license types, origins, and code quality at scale. In turn, this makes addressing license compliance, author rights, and overall data quality practically impossible.
- Lack of transparency: The Stack v2 dataset, which uses SWHIDs to identify source code, is a notable example of transparency in model training. Without similar standards across projects, it becomes impossible to scrutinize datasets for bias, licensing issues, or other critical concerns. This lack of transparency also impacts scientific reproducibility, as researchers cannot validate or replicate training data.
- Lack of attribution: When a model generates code, there’s currently no reliable way to verify whether the output resembles any training data. Without knowing exactly what’s in the dataset, users can’t attribute or responsibly use the outputs, leaving them open to legal and ethical risks.

That’s where Software Heritage comes in. We hope to address the shortcomings in the current AI landscape, mainly:
- Transparency and archiving: By providing a single, accessible archive of public code, Software Heritage enables transparent, responsible AI training. Models trained on code that’s publicly available and archived in Software Heritage can make their dataset transparent by simply publishing the corresponding SWHIDs.
- Resource efficiency and responsible use: Building qualified datasets from the Software Heritage archive will avoid duplication of effort, massively reducing resource waste, and support transparency and reproducibility. Uniform principles for creating and using these datasets will ensure that AI training will be done responsibly.
- Rich metadata support: Building the largest metadata database for source code, including licensing information, will simplify creating datasets that honor author rights, fostering respect for intellectual property.
- Standards for open dataset practices: Joining international conversations on open dataset standards, such as the Text and Data Mining reservation protocol (TDM), will allow people to communicate their usage preferences.
- Attribution and code similarity tools: Exploring techniques to trace code similarity and origins within our archive will enable developers and users to understand the roots of generated content and credit authors appropriately.
- Creating a source code and AI interest group: A dedicated Source Code and AI college will bring together committed partners who adhere to responsible principles, including in IP handling when using the archive for AI model training.
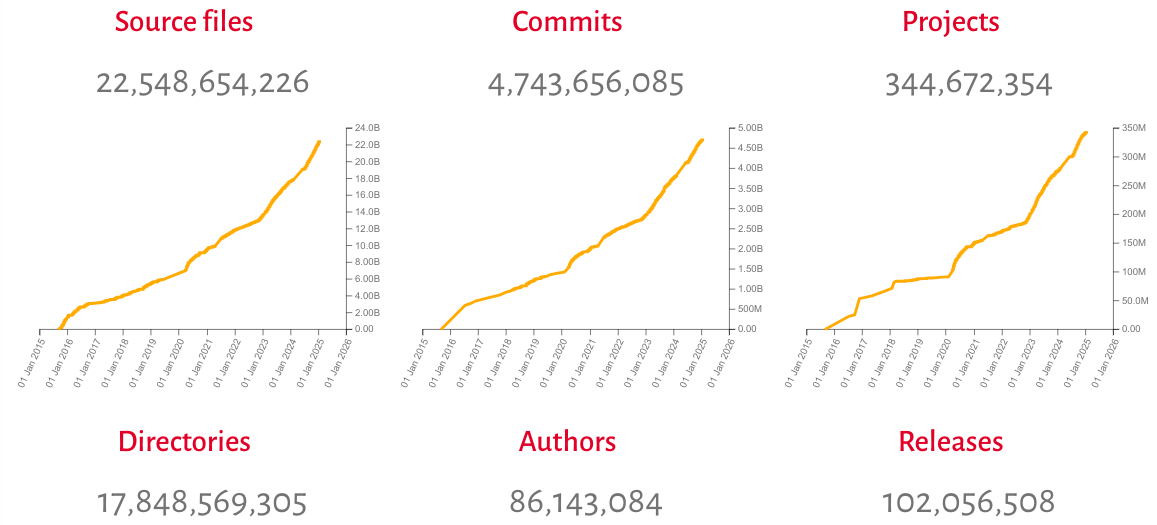
When the idea for Software Heritage germinated a decade ago, we hoped to change how people viewed software by creating the archive. After 4,708,915,582 commits, and with the support of mirrors, a global network of sponsors and ambassadors, we’ve made that shift.
Now we’re ready to take on the challenge of a transparent, open approach to AI with a project called CodeCommons. Just as when we started, we’re supported by some great partners including research teams from Inria, CEA, University of Bologna, University of Pisa, University of Torino and Scuola Superiore Sant’Anna, and AboutCode.Read more about what the teams are at work on now following the recent partner kickoff in Paris.
Stay tuned for updates as we work toward a future where AI benefits all by building on a shared, responsibly managed software heritage.