The vital role of software in Open Science

How do you prevent the crucial software of Open Science from vanishing into the digital ether? At the University of São Paulo, Roberto Di Cosmo, Software Heritage co-founder, detailed the infrastructure the organization has built to rescue and democratize the vast codebase underpinning scientific progress.
The nearly two-hour session from the leafy USP campus centered on the infrastructure that Software Heritage provides to address the critical challenges of software preservation and accessibility.
The talk highlighted that understanding software functionality and design depends on examining the source code. Di Cosmo brought up a quote from Donald Knuth, saying that having access to code humans can read is vital for real understanding. He illustrated this with a classic example: the Apollo 11 lunar module software, code we can still learn from.
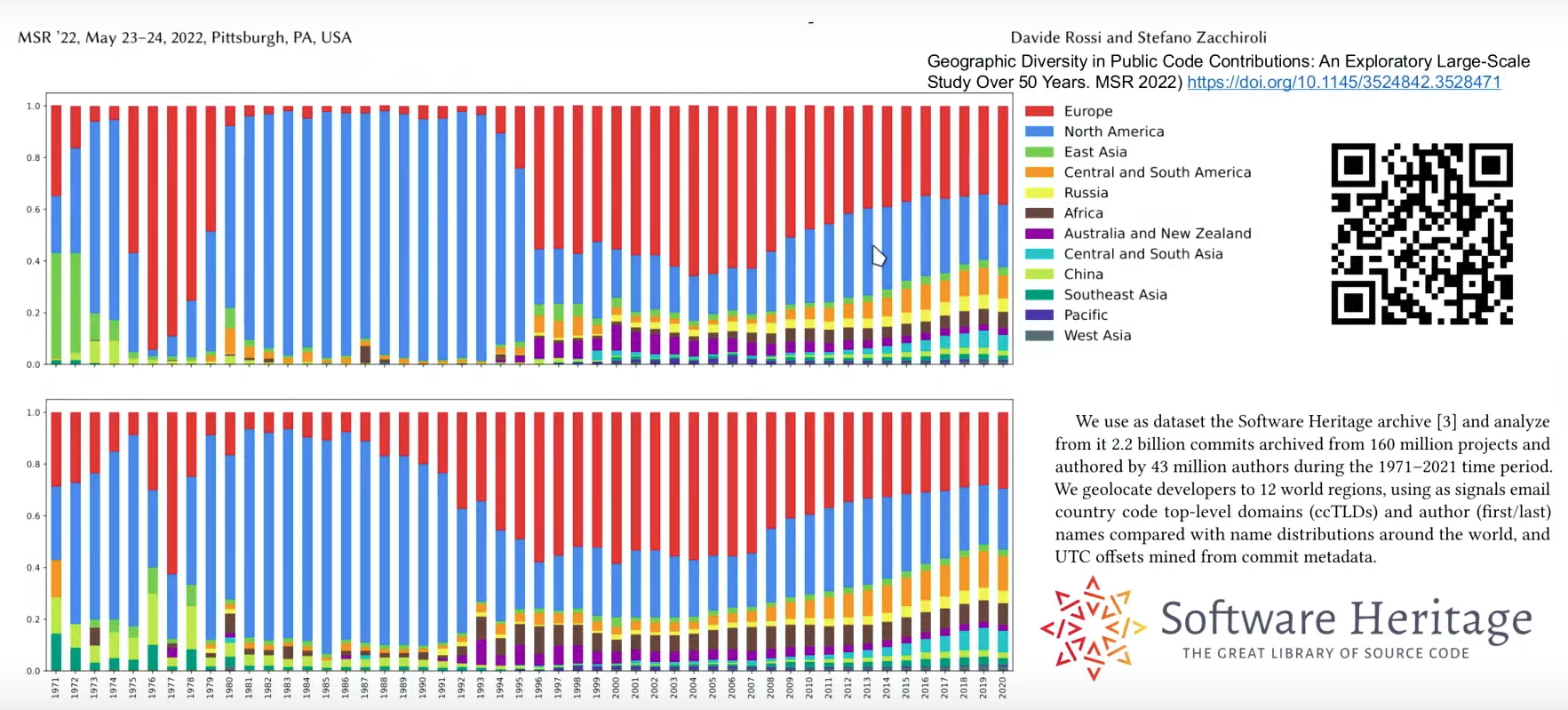
Data from the Software Heritage archive, outlined in a paper, shows the global reach of software development: Over a third of current coding occurs outside the United States and Europe, emphasizing the need for robust preservation and access mechanisms.
“The amount of source code created daily is staggering and exponentially growing,” says Di Cosmo. Analysis of the Software Heritage archive contents reveals that since the 2000s, the number of new, original pieces of software has doubled approximately every two years, even after the impact of COVID.
A key point is software’s integral role in open science, alongside open-access publications and research data. Di Cosmo stresses that the inability to access the software behind research findings undermines the ability to reproduce those findings. He cited an example where a research paper’s outcome couldn’t be verified without the associated data and specific software version used. The growing recognition of software as a vital research output is evident in initiatives like France’s National Committee for Open Science (CNRS) and the National Open Science Award for Research Software.
“We’re deeply involved in all aspects of reproducibility. What we currently provide is the ability for you, and for those reading your paper hours or years later, to access the exact version of the source code used,” he said. “However, source code alone isn’t sufficient, so we are also collaborating with others; for instance, in Debian there’s a project called reproducible builds.”

The risks of relying solely on commercial code hosting platforms for long-term software preservation were also discussed, citing examples like the shutdowns of Google Code and Gitorious.
The talk introduced Software Heritage as a crucial project, backed by Inria (a French public research institute), with a clear mission: to gather, safeguard, and provide open access to all source code. This vendor-neutral and open setup directly tackles the long-term problem of keeping software alive and available.
Some key features of Software Heritage:
- Scale and breadth: The archive currently holds over 360 million projects and 23 billion unique source files from over 5,000 platforms.
- Deduplication and integrated history: Content hashing to create a de-duplicated graph of software evolution.
- Persistent identifiers: Assigns SoftWare Heritage IDs (SWHIDs) for reliable citation and referencing.
- Research infrastructure: Provides a publicly available dataset for large-scale analysis.
- Integration and recognition: Integrates with portals like France’s HAL and provides browser extensions for archival.
Future developments for Software Heritage include global expansion of publication linking, enhancing reproducible builds, developing CodeCommons for enriched metadata, and establishing an international organization for long-term sustainability.
The talk wrapped up by urging researchers, institutions, and policymakers to get involved with Software Heritage. The message was clear: use it to keep research software safe and cite it properly, build it into open science plans, and even help make it better. Software Heritage provides vital infrastructure for ensuring the enduring accessibility and impact of software-intensive research.
Catch the full 1:50 lecture on YouTube or check out the slides.