Software Heritage features
Sharing the source code commons with a set of trustworthy and open services that provide access to the largest source code library in the world.

Browse & Search
The SWH archive is the gateway to all captured source code and its entire development history. With the browsable platform, it is possible to visualize all the visits made to a given location of the code (collected from different forges, package managers and distros) and read the source code content captured.

SoftWare Hash IDentifier (SWHID)
The SoftWare Hash IDentifier (SWHID), a universal identifier for software pioneered by Software Heritage, is officially the ISO/IEC international standard 18670. SWHID provides intrinsic, verifiable identifiers for long-term traceability and reproducibility. A major step for a more robust digital ecosystem, driven by community collaboration.

Citation feature
Software Heritage offers built-in citation support, a significant step in acknowledging software as a legitimate research output.
With this feature, researchers, users, and readers can now easily generate and copy a BibTeX citation directly from Software Heritage into their .bib files.
Citing a specific software version—or even a precise code fragment—is just as simple: select the version or highlight the lines of code, and you’re ready to go.

Download
The Vault provides a way to reconstruct and download self-contained bundles from the archive. These bundles, containing directories and revisions, can then be imported locally, for instance into a Git repository, using either the web platform or the API.
Go to the download directory API endpoint

Save Code Now
Archiving every repository globally takes time, especially with frequent daily updates. That’s why we offer the «Save Code Now» service, allowing users to proactively request a save to the SWH archive.

Deposit
The deposit feature is a SWORD 2.0 Server implementation. S.W.O.R.D (Simple Web-Service Offering Repository Deposit) is an interoperability standard for digital file deposit. The deposit allows a client (a repository, e.g. HAL) to submit software source archives and its associated metadata to the SWH archive. Metadata can be also submitted referencing a repository url (origin) or a SWHID.

Add Forge Now
With the «Add forge now» service, Software Heritage users can submit a forge URL to be included in our regular archiving schedule.
All of these requests undergo a validation workflow that includes curation and a compatibility check with Software Heritage’s tools.

Crawling
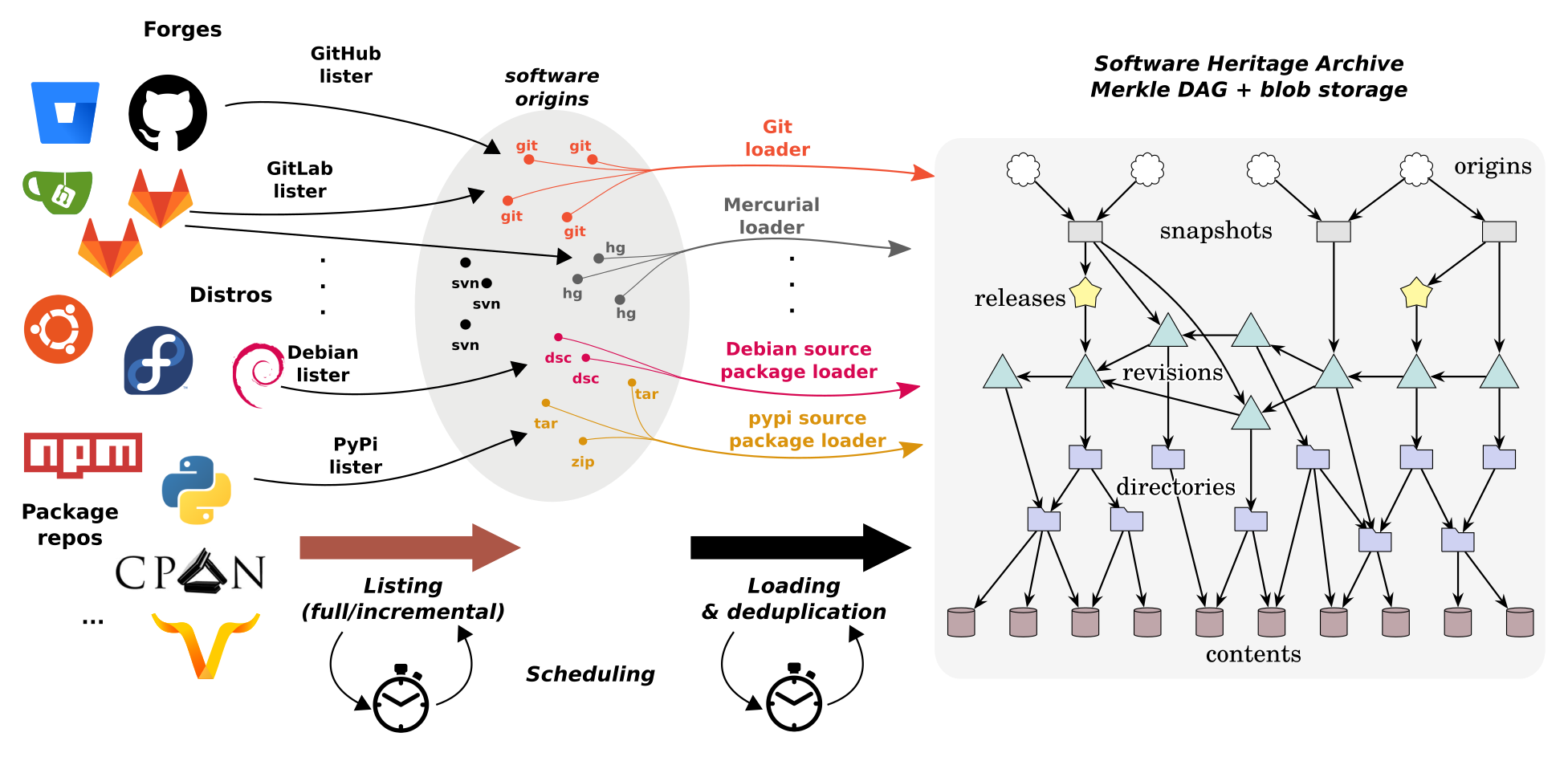
The SWH archive harvests source code from numerous sources and converts all the source code into a single and universal data structure, an enormous Merkle-directed acyclic graph [Merkle, 1987], a classical cryptographic construction that combines a tree and a hash function.
There are three phases: Listing software sources, scheduling updates, and collecting the software artifacts into the archive.
Behind the scenes
Archiving all source code is a significant challenge, so we’ve implemented various mechanisms to ensure its preservation from various sources.

API
API access is over HTTPS. All API endpoints are rooted at https://archive.softwareheritage.org/api/1/ and the data is sent and received as JSON by default.
You can jump directly to the endpoint index , which lists all available API functionalities, or read on for more general information about the API.

Architecture
Archiving forge repositories and package manager source code are different processes, a complexity amplified by the evolution of version control. The SWH architecture harmonizes these varied sources into a robust system.

Data model
Software Heritage’s data model organizes collected information around «software artifacts,» with a hierarchy of contents, directories, revisions, and releases. Provenance is tracked using origins, visits, and snapshots. Read more in Software Heritage: Why and How to Preserve Software Source Code.

Mirrors
SWH mirrors are full copies in sync with the Software Heritage universal source code archive, operated independently from the Software Heritage initiative. Mirrors improve software availability, prevent information loss, and ultimately ensure unfettered access to software source code for all, reducing the risk of data loss due to uncontrolled events.

Metadata
SWH collects and extracts metadata that describes and provides additional information on source code.
- Extrinsic metadata are metadata which aren’t found in the software source code.
- Intrinsic metadata are metadata included in the source code, in a specific file or as part of a source code file.
Indexing
The swh-indexer module is responsible for processing source code files to extract information with the following objectives:
- mimetype
- ctags
- language
- fossology-license (detecting the license of a file)
- Intrinsic descriptive metadata which can be found in metadata files in the source code (e.g package.json, codemeta.json, pom.xml)