CodeCommons: Building better artificial intelligence through open source

CodeCommons is a two-year project building on the foundation of Software Heritage, the world’s largest public source code archive. Funded by the French government with academic partners in France and Italy, our mission is to expand and enhance the archive, consolidating critical, qualified information needed to create smaller, higher-quality datasets for the next generation of responsible AI tools. It prioritizes transparency and traceability, empowering model builders and users to respect creators’ rights while fostering a more sovereign and sustainable approach to AI development, massive software analysis, and reproducibility in research.
Why CodeCommons?
As AI-driven software development accelerates, the need for large-scale, well-structured, and traceable datasets has become paramount. Current AI models for software development rely on datasets mostly hidden behind closed doors, hindering accountability and reproducibility while wasting large amounts of time, compute, energy, and effort by redundantly harvesting source code. A small number of datasets are openly available but lack a clear roadmap for maintenance and evolution. Additionally, they take a suboptimal approach to license analysis and attribution, which are costly tasks that private actors are reluctant to invest in.
CodeCommons addresses this by:
- Aggregating and structuring all publicly available software source code.
- Enriching code repositories with extrinsic metadata, including discussions, dependencies, and contextual information.
- Enriching code repositories with intrinsic metadata, including license, programming language, software quality, dependencies, and vulnerability information.
- Building an attribution graph to support giving credit to authors.
- Enhancing software reproducibility and sovereignty by providing an independent, non-profit, and well-maintained archive.
Technical foundations
At its core, CodeCommons is built on Software Heritage, which has been archiving and indexing publicly available source code since 2015. The initiative builds on several related projects, like SoFAIR and SWHSec, and brings many technical enhancements, highlighted in the graphic and detailed below.
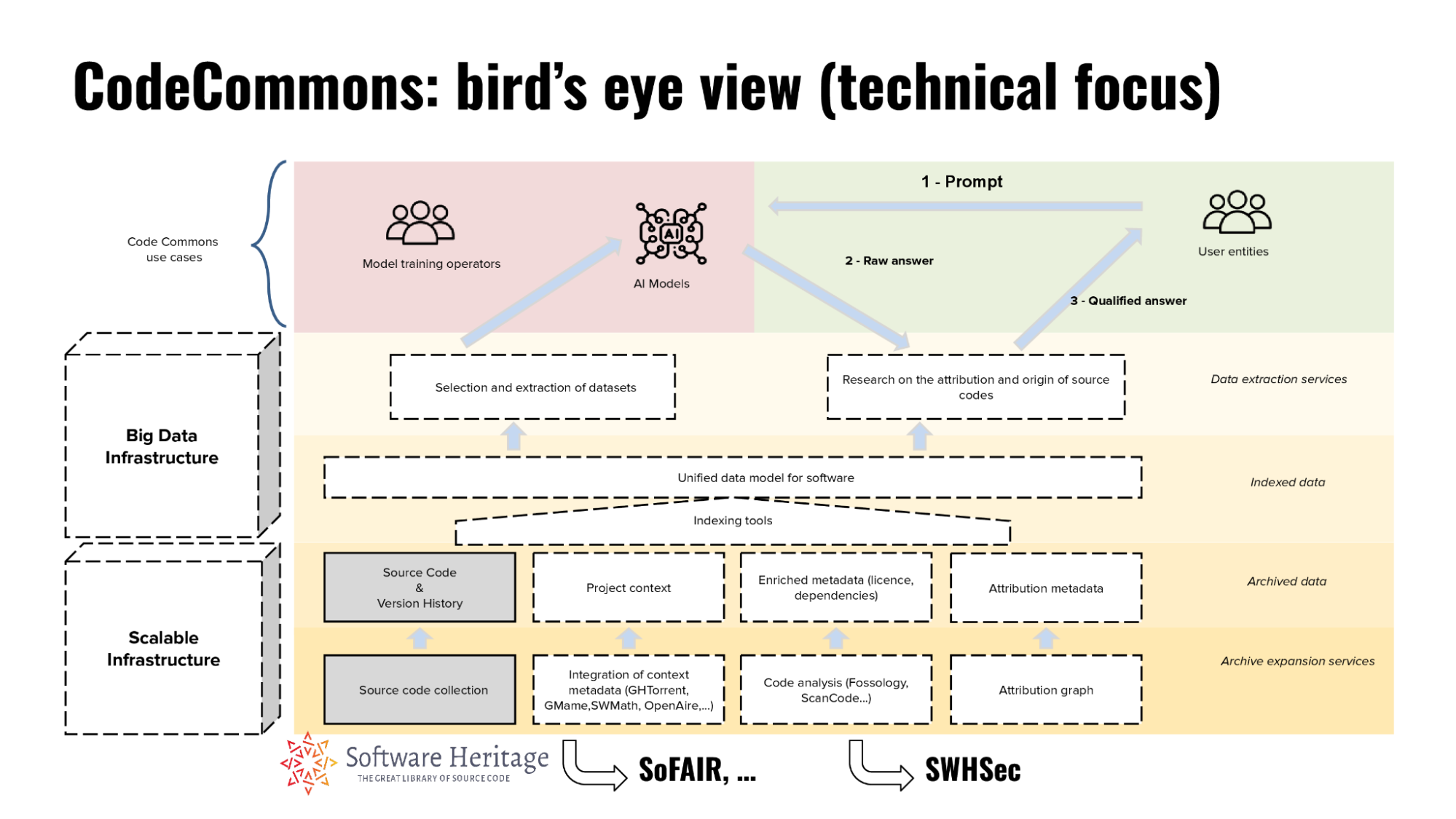
1. Scalable infrastructure for source code ingestion and qualification
The software ecosystem is growing at a whiplash pace, with original content doubling roughly every two years, as evidenced in the chart below.
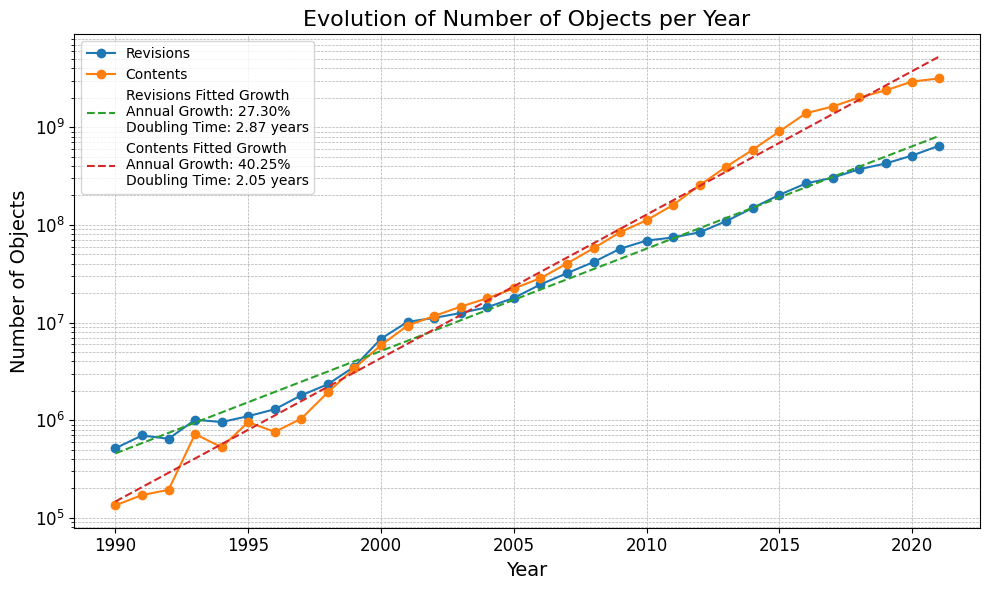
To keep pace with this exponential growth, CodeCommons will expand Software Heritage’s capabilities to:
- Accelerate code ingestion from existing and new repositories.
- Improve indexing efficiency to optimize storage and retrieval.
National high-performance computing (HPC) infrastructures, through CINES and GENCI, will allow, for the first time, the state-of-the-art analysis needed to achieve the desired quality of results. To support out-of-the-box access to the archive for code analysis tools, the swh-fs file system interface will be overhauled, focusing on efficiency and leveraging groundbreaking work on the Software Heritage compressed graph and the forthcoming compressed object storage.
To collect extrinsic metadata for hundreds of millions of repositories, we’re exploring several approaches, starting from work done in GHTorrent (deprecated), and GitHub Archive, still operational.
To address copyright licenses and attributions, we’re working with AboutCode to run scancode tools on an unprecedented scale: tens of billions of source code files.
Finally, specific data processing pipelines will be set up to remove personally identifiable information and inappropriate or irrelevant content, starting from the data preparation open source toolkit.
2. Unified data model and enhanced querying
To make AI training and software analysis easier, CodeCommons is developing a unified data model that will:
- Structure software artifacts into an indexed, searchable format.
- Allow extraction of relevant subsets based on criteria such as programming language, license type, or historical versioning.
- Enable efficient querying to support large-scale machine learning applications, software analysis, and reproducibility in research.
- Incorporate tools to filter content, with a focus on data privacy in AI.
We’ll collaborate with projects like SWHSec to integrate information on vulnerabilities, and with SOFair to establish the connection between software projects and the scientific literature.
3. Advanced provenance and attribution mechanisms
A key innovation of CodeCommons is its focus on traceability, using:
- SWHID (Software Hash Identifier): A persistent, content-based identifier that ensures reproducibility and transparent referencing of software artifacts. It’s on track to become an international standard as ISO/IEC DIS 18670.
- Enhanced attribution graphs: Linking source code files to their original repositories, authors, and discussion threads, fostering ethical AI training practices and compliance with open-source licensing.
4. Code similarity tools and model training baseline
Because code attribution depends on comparing model-generated code to its training data (which can be billions of files large), efficient comparison methods are essential. To tackle this challenging task, we’ll explore both classic and AI-based approaches to clone detection at a massive scale. This will build on cutting-edge research work from world-class experts on text algorithms from Scuola Superiore Sant’Anna, and vector embedding work by the academic consortium.
A testing framework and baseline information will be established to compare the performance of current models—built using massive amounts of code for training—against a new approach based on smaller, higher-quality training datasets.
Applications and impact
CodeCommons is designed to serve a wide range of stakeholders:
- AI researchers: Providing transparently sourced and structured training datasets for generative AI in software engineering.
- Open-source developers: Encouraging the development of transparently trained, open AI models that users can freely use, with clear attribution for contributions.
- Scientific communities: Offering tools for software discovery and reuse while enabling reproducibility in computational research by preserving the full history of software artifacts.
- Regulatory and compliance bodies: Ensuring AI training datasets comply with standards on transparency and traceability.

Thanks to all the researchers and participants from: AboutCode, Tweag, CEA, DiverSE, ALManaCH, Cedar, Scuola Superiore Sant’Anna, Scuola Normale Superiore, Università di Pisa, Università degli Studi di Torino.
A collective effort
The vision of CodeCommons is to build a trusted and transparent resource for the next generation of AI. We’ve brought together a broad range of expertise from top academic researchers and engineers to achieve this goal, but contributions from the larger community will be instrumental to success.
This project empowers developers, researchers, and the broader AI community to create more responsible and sustainable AI applications by giving them the data they need.
Sign up for updates with the CodeCommons newsletter or read more about Software Heritage and AI.