
Les données numériques peuvent être perdues, altérées ou rendues inutiles dans de nombreuses situations.
- Une intervention humaine accidentelle ou malveillante peut conduire à la suppression d’informations importantes. L’absence de procédures de sauvegarde mais aussi des procédures imparfaites ou non testées peuvent par ailleurs empêcher leur récupération.
- Les changements dans les formats logiques ou la perte de l’environnement d’exécution requis peuvent aboutir à l’impossibilité d’accéder, de lire, d’interpréter, de valider ou d’utiliser les informations numériques.
- L’absence de mécanismes de référence ou leur caractère inapproprié peuvent détruire notre capacité à identifier les informations pertinentes, même si elles ne sont pas perdues et restent lisibles par ailleurs.
- Le chiffrement protège notre vie privée, mais empêche également la récupération des informations si les clés sont perdues.

Quelques exemples valent mieux que 1000 mots

Code source manquant, à une très grande échelle
Nous ne saurons jamais à quel point les efforts gigantesques consacrés à la résolution du fameux bug de l’An 2000 (ou Y2K) avant le 31 décembre 1999 ont été efficaces : les grandes catastrophes annoncées n’ont jamais eu lieu, mais est-ce parce que les principales occurrences du bug ont été résolues à temps ou simplement parce qu’aucun bug important ne s’est en réalité produit ?
Quoi qu’il en soit, la course pour la résolution du bug Y2K a montré que dans 40 % des cas, les organisations affectées (industries, institutions, etc.) avaient perdu ou déplacé le code source du logiciel qu’ils avaient besoin de corriger. Dans certains cas, ils n’avaient même jamais eu le code source entre les mains !

Attaque malveillante de l’infrastructure logicielle
Au cours de l’été 2014, un pirate qui avait réussi à accéder au panneau de contrôle de Code Spaces réclama de l’argent pour redonner le contrôle à l’équipe de la startup (voir le site Web de Code Spaces depuis août 2014).
Code Spaces n’ayant pas obtempéré et ayant essayé de reprendre le contrôle de ses propres services, le pirate a commencé à détruire des ressources.
Code Spaces était une société proposant des solutions d’hébergement pour le développement de logiciels, et cette attaque mit sérieusement en danger tous les logiciels hébergés sur son site.
Arrêt des services de développement de logiciels
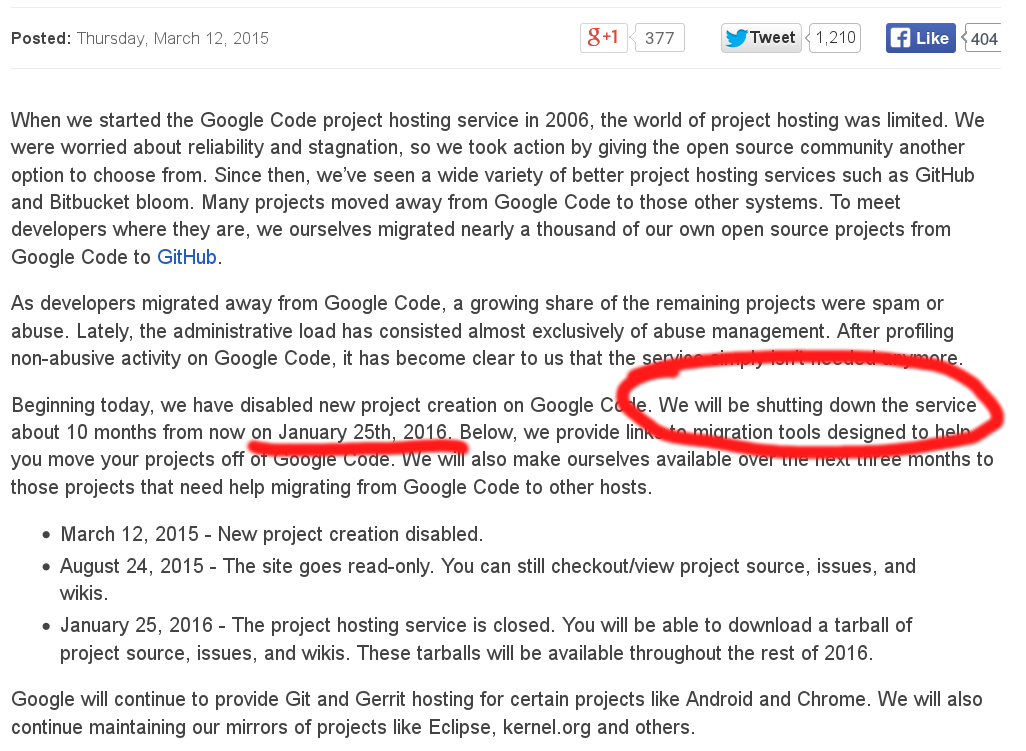
En mars 2015, Google a annoncé l’arrêt de Google Code, un service largement utilisé et très apprécié, lancé en 2006.
Malgré l’annonce d’un calendrier de migration, fin 2016, tout le code hébergé par ce service aura disparu, à quelques exceptions près.
Que deviendront les logiciels importants dont plus personne n’assure la maintenance en ligne ? Qui prendra soin de toutes ces connaissances qui risquent d’être perdues ?
Arrêt des services de développement de logiciels (encore)
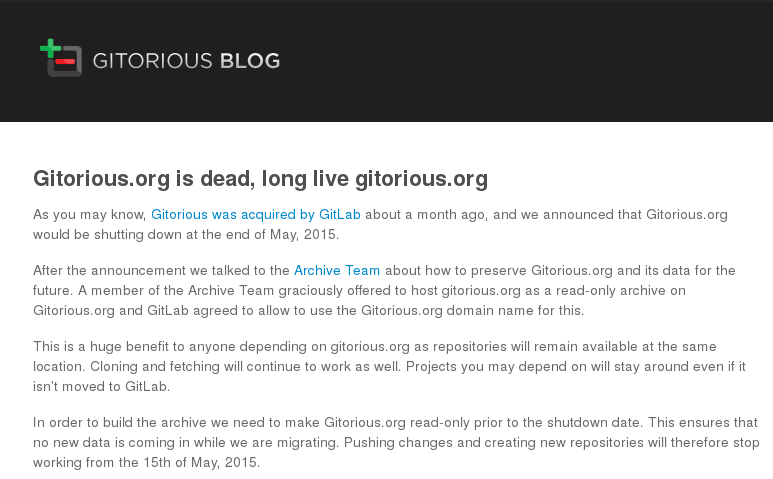
En mai 2015, Gitorious a également annoncé qu’il allait mettre fin à ses services d’hébergement pour le développement de logiciels libres. Merci à l’Archive Team pour son travail ; une copie en lecture seule des projets logiciels initialement développés sur Gitorious sera conservée. Mais pendant combien de temps ?
Et que ferons-nous lorsque se produira la prochaine fusion, la prochaine acquisition ou la prochaine réorientation des priorités commerciales de certains acteurs majeurs dans le développement des logiciels ?

Mécanismes de référence inappropriés
Il est bien connu que les URL (Uniform Resource Locators, localisateurs de ressources uniformes) ne garantissent pas la persistance.
… il n’existe aucune garantie générale qu’un URL qui pointe vers un objet donné à un certain moment continuera de le faire
T. Berners-Lee et al. RFC 1738
Et pourtant, cela reste le mécanisme le plus communément employé aujourd’hui pour référencer les informations qui doivent être accessibles à long terme, tels les articles scientifiques, avec des conséquences désastreuses lorsqu’il faut retrouver le logiciel qui est important pour une expérience ou une application particulière.
… un URL référencé a une demi-vie d’environ 4 ans à compter de la date de sa publication
D. Spinellis. The Decay and Failures of URL References.
Communications de l’ACM, 46 (1) : 71-77, janvier 2003.
Le projet Software Heritage
Nous construisons la plus grande archive de code source de logiciels qui ait jamais vu le jour. Nous nous efforçons de supprimer définitivement le risque de perdre un logiciel important ou l’historique de son développement. Nous nous efforçons de maximiser les chances de conserver dans son intégralité notre bien commun logiciel.