A pillar of Open Science
“Software should be considered a legitimate and citable product of research.” — Software citation principles
“Non-reproducible single occurrences are of no significance to science”
— Karl Popper, The Logic of Scientific Discovery, 1934
“Sometimes, when you do not have the software, you do not have the data.”
— Christine Borgman, JNSO 2018
Guidelines for archiving and referencing software artifacts
Guiding you all along the journey

Step 3: reference your work
Once your source code has been archived, there are many ways to reference it in your article. Three common use cases are
- adding a link to the full repository archived in Software Heritage
- adding a link to a precise version of the software project
- adding a link to a precise version of a source code file, down to the level of the line of code.
The full repository
The link to the full repository archived in Software Heritage (with all its development history) is obtained by prepending to the URL you used to request its archival the prefix https://archive.softwareheritage.org/browse/origin. For example, if the repository you have saved is https://github.com/rdicosmo/parmap, then the link to the saved version in Software Heritage will be
https://archive.softwareheritage.org/browse/origin/https://github.com/rdicosmo/parmap/
Following this link, your readers can browse the contents of your repository extensively, delving into its development history, and/or directory structure, down to each single file.
Using Software Heritage intrinsic identifiers (SWHID)
Software Heritage provides a fully documented standard identifier schema, called SWHID, to equip any software artifact with intrinsic identifiers. A full discussion of the properties that make SWHIDs the identifiers of choice for reproducibility can be found in a dedicated research article, and you can learn more about its growing adoption in a dedicated blog post.
SWHID can be equipped with a rich set of qualifiers that can make precise the context in which a given artifact is meant to be seen.
Here we give just a few examples of how they can be used.
Specific version of the project
The following SWHID identifies a precise version of the source code of Parmap:
swh:1:rev:0064fbd0ad69de205ea6ec6999f3d3895e9442c2;origin=https://github.com/rdicosmo/parmap
SWHIDs can be turned into a clickable URL by prepending to them the prefix https://archive.softwareheritage.org/. So, the following (hyper)link brings you directly to a page in Software Heritage that is browsing that precise version (try it!)
A very simple way of getting the right SWHID is to browse your archived code in Software Heritage, and navigate to the revision you are interested in. Click then on the permalinks vertical red tab that is present on all pages of the archive, and in the tab that opens up you select the revision identifier.
Version 1 of the SWHIDs uses git-compatible hashes, so if you are using git as a version control system, you can create the right SWHID by just prepending swh:1:rev: to your commit hash.
Code fragment
SWHIDs as supported by Software Heritage allow you to go even further and pinpoint a given fragment of code inside a specific version of a file, by using the lines= qualifier available for identifiers that point to files. For example, the following SWHID, that showcase all the available qualifiers for content SWHIDs, points to the core mapping algorithm inside the Parmap source code as presented in a research article describing Parmap back in 2012:
swh:1:cnt:d5214ff9562a1fe78db51944506ba48c20de3379; origin=https://gitorious.org/parmap/parmap.git; visit=swh:1:snp:78209702559384ee1b5586df13eca84a5123aa82; anchor=swh:1:rev:0064fbd0ad69de205ea6ec6999f3d3895e9442c2; path=/parmap.ml; lines=101-143
Test it by clicking on this link: you will be brought seamlessly to the Software Heritage archive on a page showing the corresponding source code, with the relevant lines highlighted.
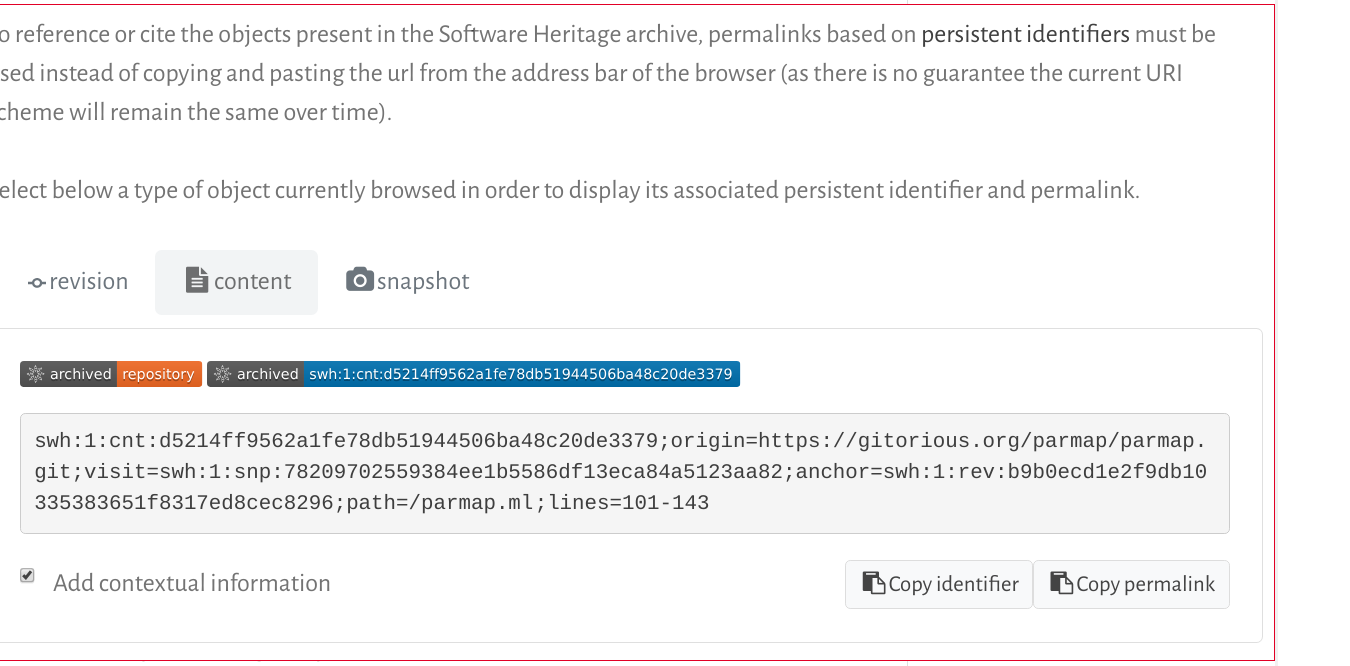
Here too, you can get the exact link by navigating to the code fragment you are interested in the archive, click on the line number of the first line of the fragment, shift-click on the last one, and then open the permalinks tab.
Bibliography entries for Software
Last but not least, biblatex-software, a bibliographic style that makes full use of SWHIDs is now available for BibLaTeX users from CTAN. See the documentation there to learn more!
Get the Guide
The latest version of Software Heritage’s research software guidelines and walkthrough with LaTeX examples, can be downloaded here.

Contribute to the Guide
The source code of the guide itself is available and distributed under a CC-BY 4.0 license. You are welcome to contribute to improve it. It will be updated regularly.

Join the community
A mailing list for sharing information among the scientific community on research aspects of Software Heritage is available, and you are welcome to join.