Looking for detailed guidelines? Go to the HOWTO archive and reference research software.
A pillar of Open Science
“Software should be considered a legitimate and citable product of research.” — Software citation principles
“Non-reproducible single occurrences are of no significance to science.”
— Karl Popper, The Logic of Scientific Discovery, 1934
“Sometimes, when you do not have the software, you do not have the data.”
— Christine Borgman, JNSO 2018
Software has become a pillar of research, ubiquitous in all its fields: a large part of the technical and scientific knowledge being developed today is described in the software source code at a level of detail that is often needed to remove ambiguities that may exist in intuitive descriptions. The preservation of this universal body of knowledge is as essential as preserving research articles and data sets.
We must preserve three main pillars: research articles that describe the results, the data sets used or produced, and the software source code that embodies the logic of the data transformation.
Relying on Software Heritage: benefits for researchers
A giant library integrated into the scholarly ecosystem
Software Heritage builds bridges between academia and the rest of the software world. The source code library collects all available source code and fosters partnerships for research software. Software Heritage collaborates with scholarly infrastructures, including institutional repositories, publishers, and aggregators to support the archival, reference, description, and citation of research software.
These collaborations are established to deposit software artifacts into the universal archive, exposing SWHIDs in the different infrastructures metadata records, exchanging curated metadata, and exporting citation information in common open formats like BibLaTeX and codemeta.json.
Software Heritage has also built strong partnerships with different scholarly infrastructures worldwide, including publishers such as eLife or Dagstuhl.
Supporting researchers in their quest for more reproducible research
To guide you on your journey, here are detailed guidelines on how to archive and reference research software.

The Software Hash Identifier – SWHIDs for Academia
Building a solid web of knowledge that lasts over time is of paramount importance for academia. A key component of this is the connection between the different research outputs, and for this reason, references, citations, and various systems of identifiers have been used for centuries, well before the computer era. These systems of identifiers come in two broad categories:
Extrinsic: use a register to keep the correspondence between the identifier and the object
Intrinsic: intimately bound to the designated object, they do not need a register, only agreement on a standard
For more details on the differences between intrinsic and extrinsic identifiers, follow this link.
The DOI, an extrinsic identifier, is a Persistent IDentifier (PID) widely used by researchers to identify academic outputs, including data sets. However, the software calls for specific solutions to identify different types of source code artifacts. Software Heritage ensures the long-term availability of artifacts with their complete development history.
Software Heritage provides a Persistent IDentifier (PID) that can identify each source code artifact with integrity, called a SoftWare Hash Identifier (SWHID). SWHIDs are intrinsic identifiers that are intimately bound to the designated object; they do not need a register, only agreement on a standard to resolve them. Thus, by referencing a software artifact with a SWHID, one can ensure precise identification of artifacts at various levels of granularity.
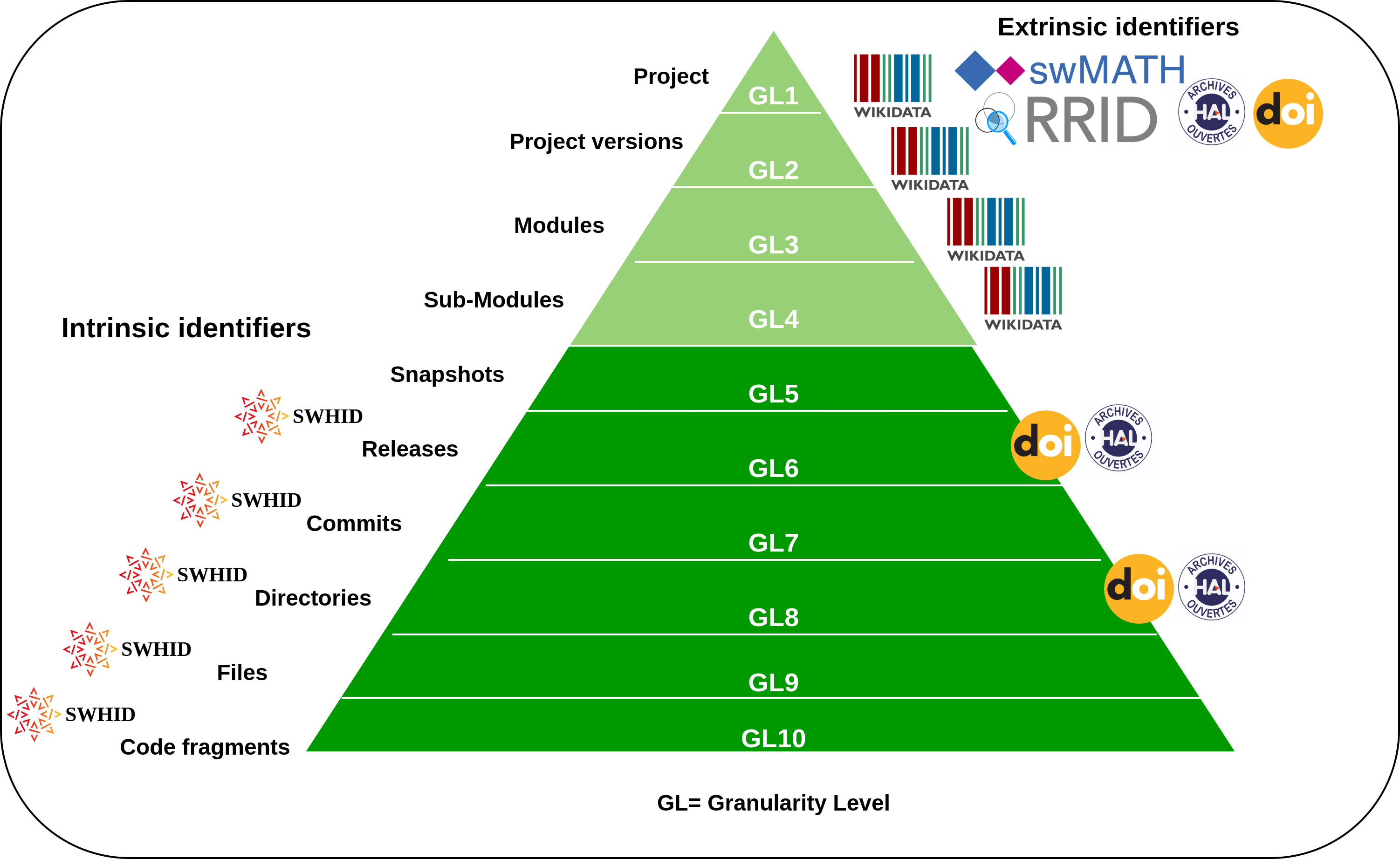
Credit: Research Data Alliance/FORCE11 Software Source Code Identification WG, 2020, https://doi.org/10.15497/RDA00053
Software authors deserve credit
Researchers in many domains are using software for their work and some are creating software to support their research. To promote Open Science and Open Source Software researchers who develop software should be recognized in their endeavour.
Why Software Attribution Is Challenging
Citations tools and features: from metadata to credit
In 2020, the biblatex-software package was released to any LaTeX user to cite a software artifact in a few clicks. More details on the biblatex-software package are described here.
The road ahead: an interconnected landscape for Academia
The landscape of research software is intricately linked to a vast and diverse software ecosystem, making it challenging to ensure consistent practices across different platforms and disciplines. Supporting open infrastructures that serve both research software and the researchers who develop and use it is critical. Institutions must identify and promote key roles that support researchers in making their software open source, FAIR, citable, and reproducible. However, achieving high-quality metadata and rigorous peer-review of software artifacts comes at a significant cost, both in terms of time and resources. Additionally, there is a pressing need for a cultural shift within the research community to recognize software not just as a tool but as an essential component of research, an outcome of the research process, and a research object in its own right.
As we move forward there are different objectives we have identified:
- Developing infrastructure capabilities to effectively manage software metadata. This involves refining our metadata workflow and the deposit mechanism, clearly defining roles, and standardizing metadata management to align with global best practices.
- Engaging this community is not just about building software components—it’s about fostering an ecosystem that supports open science and the preservation of software as a critical research output. This community engagement will involve facilitating workshops and providing platforms for collaboration and feedback.
- Training and education with Software Heritage Academy. Providing training and resources to help stakeholders, including developers and curators, to better understand and use the existing features, tools, and services.
Moreover, as technology evolves, there is a need to stay at the cutting edge. Integrating advanced technologies like AI and machine learning can automate and improve the efficiency of curation and interconnection processes.
The road ahead is about continuing to build the software pillar of Open Science. It involves technical development, community engagement, sustainability efforts, and a commitment to continuous improvement and adaptation.
Get the Guide
The latest version of Software Heritage’s research software guidelines and walkthrough with LaTeX examples, can be downloaded here.

Contribute to the Guide
The source code of the guide itself is available and distributed under a CC-BY 4.0 license. You are welcome to contribute to improve it. It will be updated regularly.

Join the community
A mailing list for sharing information among the scientific community on research aspects of Software Heritage is available, and you are welcome to join.